

Crossbeam recently migrated its data pipelines to Temporal, a powerful data pipeline orchestration tool. As a Clojure shop — a robust, practical, and fast programming language — we were looking for a tool that would integrate seamlessly with our existing codebase.
Temporal provides our software team with in-code abstractions and granular control over our data pipelines. Additionally, the Clojure community is actively developing a Temporal Clojure Software Development Kit (SDK), wrapping the Temporal Java SDK.
The migration process had its challenges, but with support from the Clojure community and thorough testing, it was manageable. We’ve been running Temporal in production for a while now with minimal issues.
A Temporal survival guide
At its core, Temporal is all about executing units of work.
In Temporal, a unit of work is defined against a Temporal service using gRPC — a cross-platform, high-performance Remote Procedure Call framework — which schedules the unit of work on a Temporal worker. Temporal workers operate within a worker pool, similar to Kubernetes pods.
Here’s a breakdown of how Temporal handles a unit of work:
-
A Temporal client schedules the work against the Temporal platform.
-
The Temporal platform uses its state machine/history to create a new unit of work on a worker.
-
The worker executes that unit of work against the application code.
-
The results are reported back to the Temporal platform.
Temporal defines several key terms (learn more about Temporal
here):
-
Activity: The smallest unit of work. It includes business logic that is idempotent (i.e., it can be safely retried) and always produces the same result with the same input.
-
Synchronous Activity: Runs until it is completed and blocks subsequent activities.
-
Asynchronous Activity: Returns immediately and allows other work to run concurrently.
-
Workflow: Encapsulates multiple activities into a single construct. This is the main unit of work that starts against Temporal.
To learn about how we transformed Crossbeam’s data pipeline, this article takes you through our journey in six key steps using Temporal:
-
Migrating our data pipelines
-
Refining the migration process
-
Scheduling with precision
-
Streamlining pipeline releases
-
Configuring efficient gRPC payloads
-
Batching activities for optimized performance
Let’s dive in!
Step 01: Migrating the data pipelines
It is easy to represent an existing data pipeline as a set of activities within a workflow, which means migrating to Temporal starts with a Workflow.
The Clojure SDK defines Workflows with macros (a command or a batch of commands executed by single action), since the code definitions are just functions. At Crossbeam, our existing data pipeline was a series of functions, so our migration to the Temporal abstraction involved refactoring those functions into workflows.
Here is a generalized example of how our code looked after it was refactored into a Workflow.
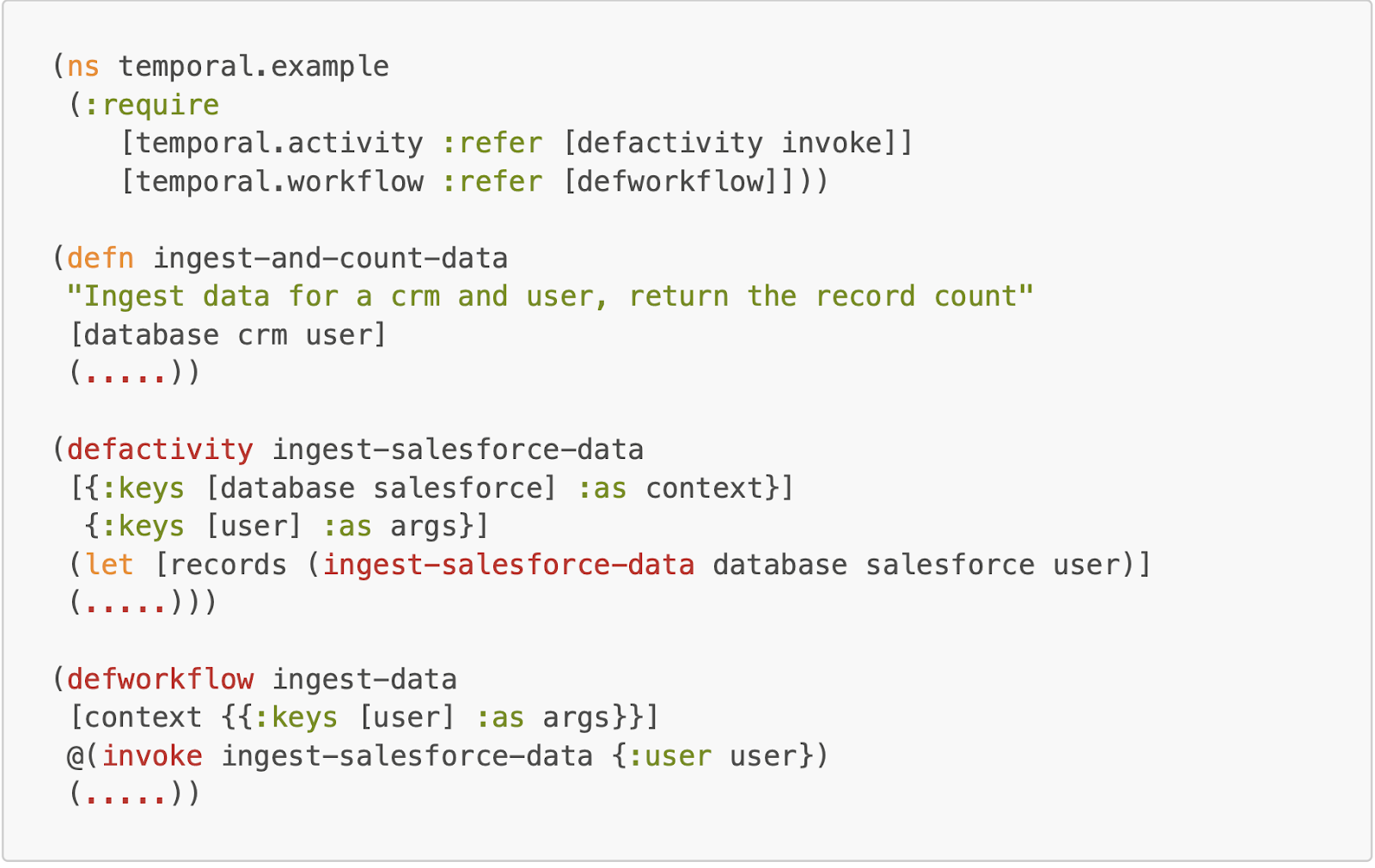
We import the macros `defworkflow` and `defactivity` to get started. We then define the activity `take-customer-money` and the workflow `checkout` to call the activity. We are assuming that the input to the workflow itself is a map that defines a transaction.
Since Clojure is such a functional language, migrating to Temporal was pretty easy!
Step 02: Reiterating on the migration
Naturally, during the migration process we ran into every software developer’s worst enemy: code duplication.
Our workflows (data pipelines) consisted of a lot of activities. We started to build up lots of duplication in logging, tracking, and option passing.
We decided to use Clojure macros to reduce the duplicated code, the same tool the Clojure SDK used to expose Temporal abstractions.
First, we defined a function to wrap every workflow and activity with logging and Datadog tracing. The function `with-tracking` simply wraps the function body in a full log context and Datadog span, which is useful when reporting workflow or activity errors.
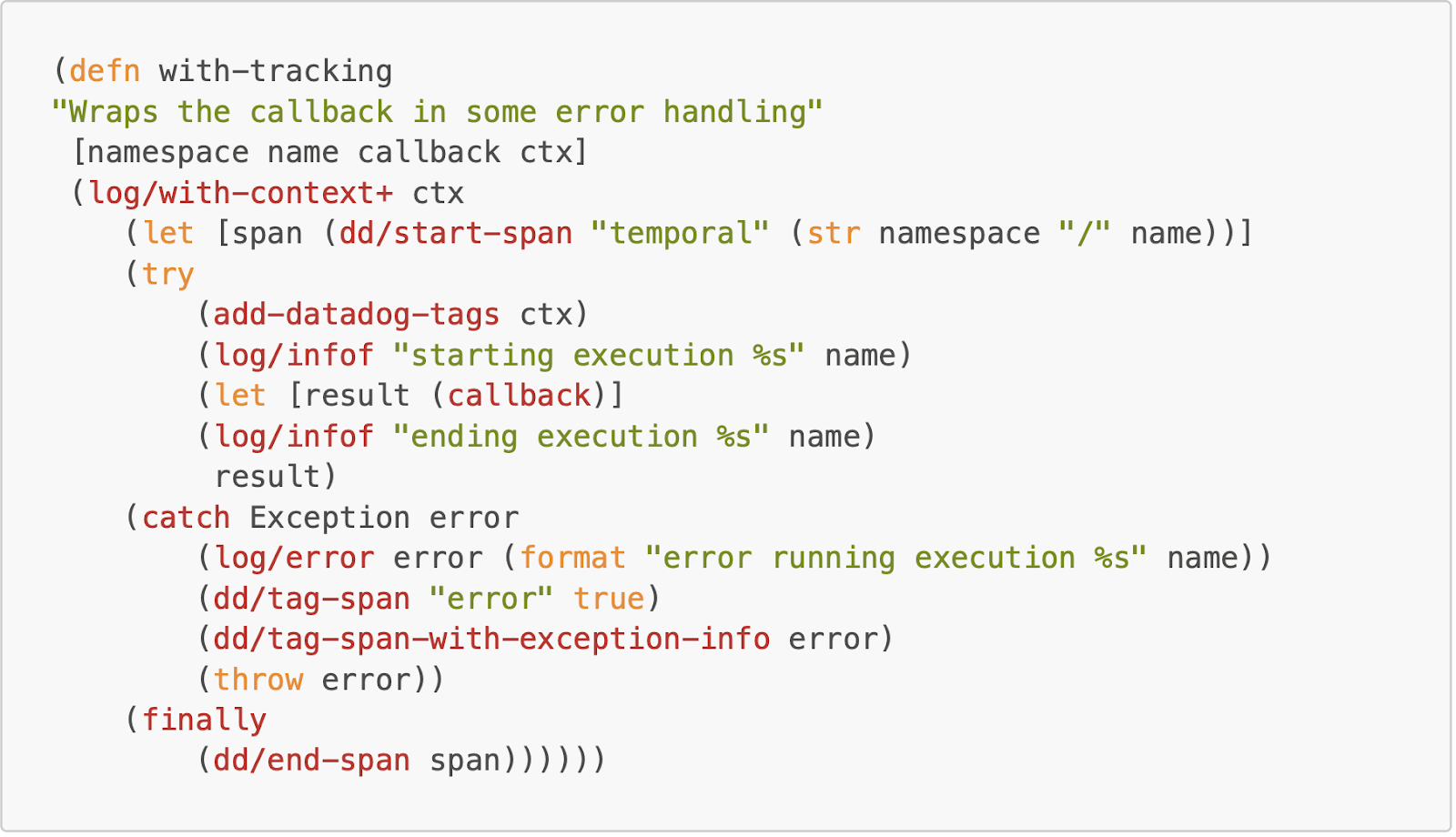
The `defactivity-with-tracking` macro added a couple of things to the existing Temporal Clojure SDK definitions. We had to generate our own arguments and then bind them to the actual params (it’s a keyword that enables developers to pass in a variable number of values at once, making code more flexible and efficient) of the macro.
We did this to extract some more context from the parameters, and it was a neat introduction to more complex macro semantics. Also, the macro did not accept a doc string so we generated our own and added it to the name (symbol) of the `defactivity` as well.

By using macros we reduced the boilerplate code needed to bootstrap an activity definition and workflow definition, saving us a ton of time.
Step 03: Scheduling the data pipelines
Transitioning to Temporal required the use of schedules for our cron (a string comprising 6 or 7 fields separated by white space) jobs. Since the Temporal Clojure SDK didn’t support schedules before our migration, we implemented them ourselves by wrapping the Java SDK.
You can see our implementation here, which we’ve contributed back to the open source library.
While the implementation was uneventful (which is a great thing) we did run into one tricky area. Updating a schedule in temporal requires a function as an argument, specifically a function that implements the Java ‘Functional Interface’.
Clojure functions implement an interface called `IFn` and that is not a `Functional Interface` nor does it implement one, so as Clojure developers, we were surprised when a normal function argument didn’t work!
We solved this by using Clojure’s `reify`* to create an on the fly functional interface that wrapped a Clojure object, as shown here:

The `Functions$Func2` interface is pulled straight from Temporal. While not intuitive at first, the schedule update argument worked just fine after it was passed a Java object.
*Clojure’s reify: It creates an object implementing a protocol or interface — reify is a macro.
Step 04: Releasing our data pipelines
Once we were using Temporal live in production, we needed to ensure our long running data pipelines ran to completion or failed gracefully.
Soon after releasing a stable version of our data ingestion pipeline to production, we noticed some of our activities would keep execution slots busy and the workers would not pick up any more work. For a few clients in the 95th percentile of execution times, some steps were hours long.
Temporal will keep running until it hears back from the workers and activity task execution. When some of our long running activities died, Temporal wasn’t notified, the worker slots were used up, and Temporal was unable to schedule more work in their place.
We needed a way to make Temporal aware of these failed activities. To fix this issue, we used Temporal’s heartbeats. Heartbeats let workers ping the Temporal cluster to let Temporal know they are still chugging away.
We configured our workers to send a heartbeat every two seconds, and for Temporal to check for a heartbeat every 30 seconds. If our Temporal cluster doesn’t receive a heartbeat within that time period, it will mark the worker as dead.
We opted to start the heartbeats with a separate Java TimerTask for each activity, so that the main activity threads could run without interruption. The TimerTask class defines a task that can be scheduled to run for just once or for a repeated number of times. We scheduled each heartbeat on a single Java Timer and it runs all the heartbeat TimerTask’s on a fixed interval using one thread efficiently.
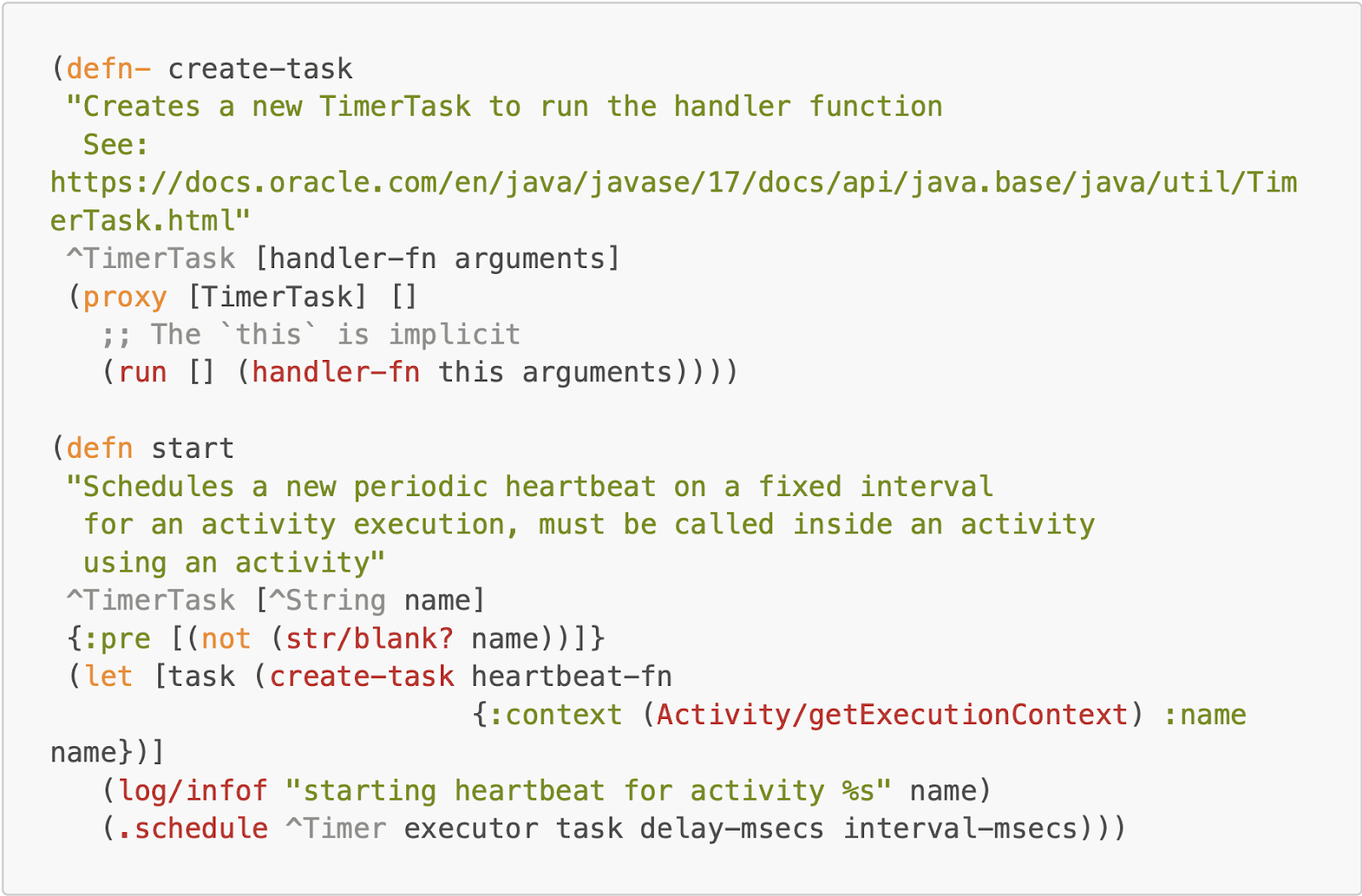
The heartbeats are removed from the Timer when the heartbeat fails or the activity reaches the end. The space is reclaimed for more heartbeats and the single Timer keeps handling heartbeats.
Temporal heartbeats stabilized our system, and allowed us to handle long-running activities more effectively.
Step 05: Configuring gRPC payloads
The Temporal Command-Line tool (CLI) tool provides an easy way to start, pause and schedule workflow execution.
A Temporal CLI provides a command-line interface to manage various aspects of Temporal, including namespaces, workflows, task queues, and more.
As a Clojure shop, we wrote scripts and wrapped them in babashka code to match other operational tools we have for the rest of our system. The CLI expected JSON (JavaScript Object Notation is a lightweight data-interchange format) input and we wanted JSON output in the Temporal UI. However, initially the Clojure SDK didn't support JSON so we had a problem.
To overcome this hurdle, we wrote our own Temporal data converters.
We used Clojure’s reify to create anonymous objects that extended `PayloadConverter` classes in the Temporal Java SDK. We manipulated the data using
nippy and encoded/decoded with JSON via the built in `clojure.data.json`
The `json-converter` decodes the UTF-8 string from the CLI input into JSON and then turns it into bytes for transit to the Temporal platform.
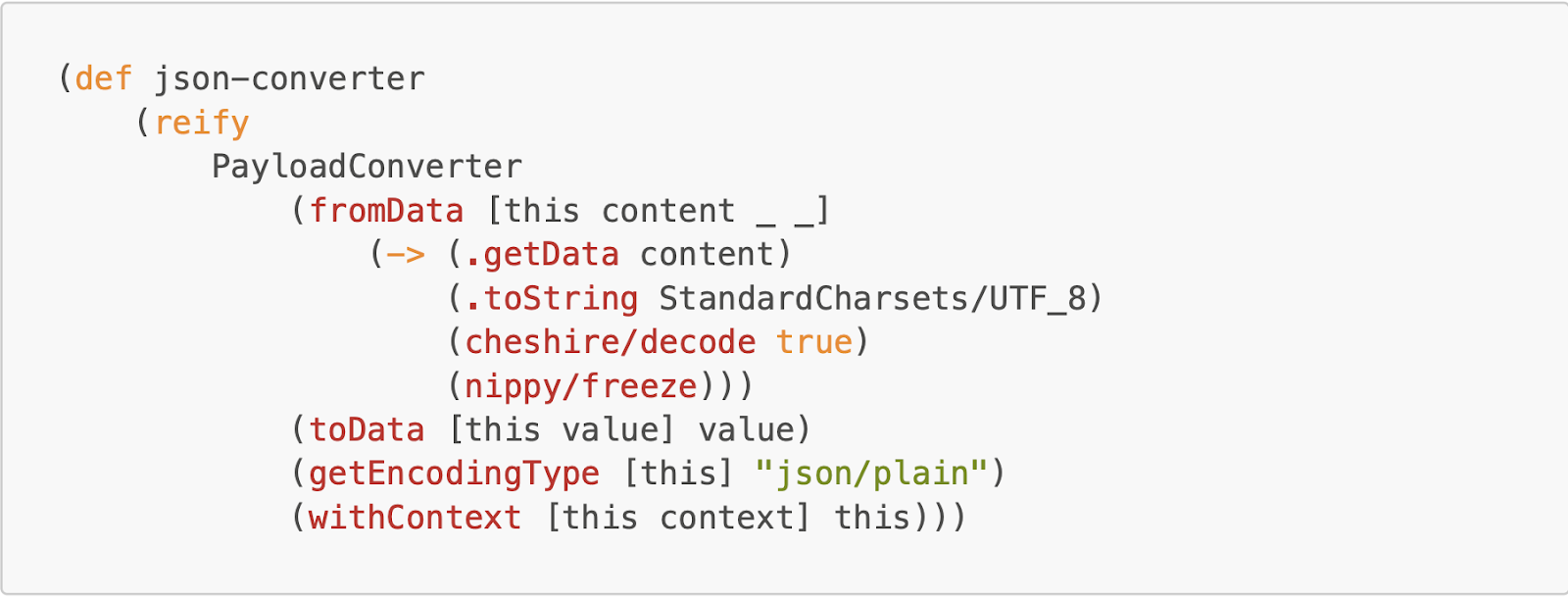
The `byte-converter` takes bytes and converts them into valid JSON for the Temporal platform to display in their UI.
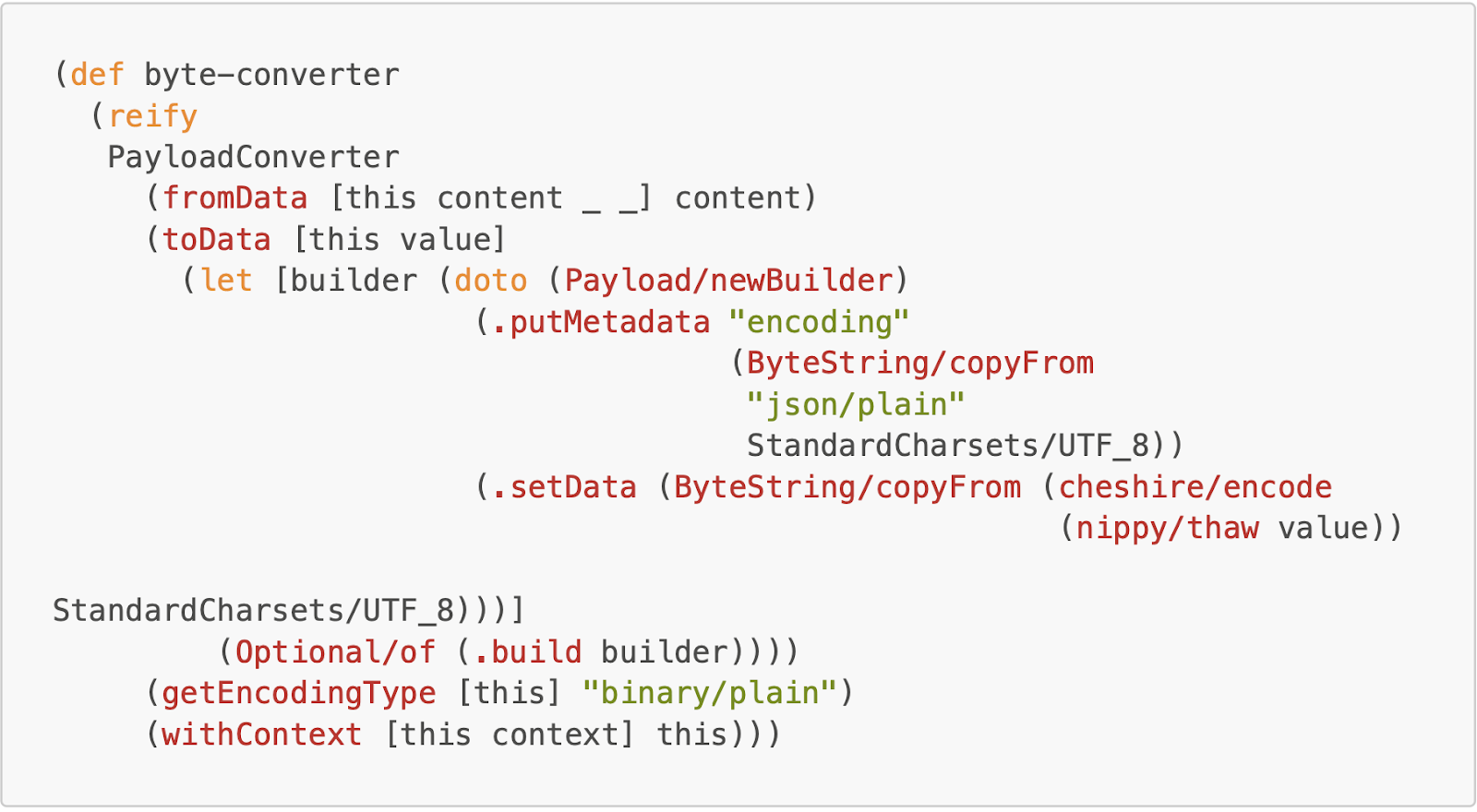
As you can see, we leveraged the Java SDK, and extended the class PayloadConverter, a binary form suitable for network transmission that may include some metadata, to handle the inputs and outputs we needed. Once these objects were created,we passed them to our Temporal client and everything from the CLI to the UI worked!
You could go a level deeper and change the way the bytes are transferred over the wire, which we might have done if we needed to implement data compression or encryption.
Step 06: Batching activities
The activities in our code are often independent, so we wanted a way to run multiple activities at the same time on one workflow. In most cases, we also did not want one failure to short-circuit the execution of other workflows.
Temporal associates each activity with a promise and allows your workflow executions to wait for all the promises to finish or fail. However, the Temporal Clojure SDK will stop at the first failure, by default.
To overcome this, we utilized the Java promise handle, enabling us to:
-
Run batches within a single workflow.
-
Wait for all batches to finish, handling exceptions gracefully.
-
Aggregate errors at the end for workflow error management.
Leveraging the built in promise type in Temporal we grabbed the `PromiseAdapter` handles.
The Promise object represents the eventual completion (or failure) of an asynchronous operation and its resulting value

This code runs all promises and waits for the result of each, swallowing exceptions,so the workflow does not crash.

NOTE: We were pretty strict on non reflection with these extensions so the `^"[Lio.temporal.workflow.Promise;"` type annotation is for an array type to avoid reflection.
Now, any part of our code can call `invoke-parallel-activities` to start looping over promises and passing to `execute-parallel-promises` aggregating the results.
One Clojure-specific note: we had to use a non lazy Clojure loop, this means that sequence elements are not available ahead of time, to avoid starting random sized chunks of processes. By default Clojure’s lazy sequences don’t give us the guarantees we would need to have total control over the batch size.

NOTE: Temporal had gRPC size limits that we had to respect with batch sizes
Now we can use this pattern to batch executions in a single workflow like so:

This implementation worked well, but there was still a ~50Mb history limit on the workflow execution in Temporal. Once we started running into the history limit, our main workflow batching the activities crashed.
To address this issue, we implemented `Child Workflows` for the Temporal Clojure SDK, which have their own history, and can be dispatched from a main workflow. With `Child Workflows` we could circumvent all of gRPC limits/pitfalls and continue chugging along activities in parallel.
Child Workflows work similarly to activities and are started under a workflow. In the example, the Child Workflows are batched and completed as promise groups to complete large batches of work.

Each Child Workflow invokes the above activities in parallel and limits the gRPC execution history limit Temporal enforces.
We ended up contributing “Child Workflows” and “all-settled” to the Temporal Clojure SDK using the built-in promise examples found here to construct the parallel batched Child Workflows with batched activities.
A final note
Temporal and Clojure make a powerful pair at Crossbeam. Leveraging macros to streamline activity and workflow definitions saved us significant development time. Clojure idioms like reify proved invaluable for extending the Java SDK and customizing data converters. Even batching promises was straightforward with non-lazy loops, giving us fine-grained control over batch sizes.
For our team, adding new Temporal workflows is now the preferred approach for orchestrating future data workflows.

